MySQL同步ES的6种方式
写在前面
我们知道,在分布式系统日益发展的今天,MySQL与Elasticsearch的协同已成为解决高并发查询与复杂检索的标配组合。但是,如何实现两者间数据的高效同步,已成为架构设计中不可忽视的问题。笔者结合实际工作经验和一些参考文章,给出常用的6种可行的同步方式,以供在后续架构设计中作参考。
小批量数据同步方式
同步双写
【适用场景】对数据实时性要求较高,且业务逻辑较为简单的场景,如支付记录同步等。
【实现方式】在代码中同时写入MySQL和ES。
【示例代码】以下是同步双写的示例代码:
1 | @Transactional |
【缺点】
(1)代码侵入:需要在所有涉及写入操作的地方都添加ES写入逻辑;
(2)性能降低:双写会导致事务时间变长,降低TPS;
(3)数据一致性难以得到保证:如果ES写入失败,而MySQL写入成功,需要引入补偿机制。
异步双写
【适用场景】对数据实时性要求不高,且业务逻辑较为简单的场景,如订单创建成功后状态修改,以供用户查询等。
【实现方式】使用MQ来进行解耦和实现异步双写。
【示意流程】以下是异步双写的流程:
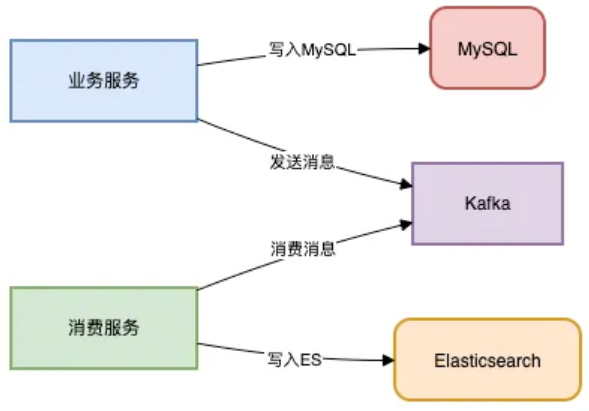
【示例代码】以下是异步双写的示例代码:
1 | //生产者(业务服务) |
【优点】
(1)大幅提升吞吐量:通过MQ实现削峰填谷;
(2)故障隔离:ES宕机不影响业务正常进行
【缺点】
(1)存在消息堆积:突发流量可能会导致消费延迟;
(2)消费顺序难以保证:必须通过分区来保证同一分区数据消费的顺序性。
Canal监听Binlog日志
【适用场景】对数据实时性要求较高,且业务逻辑较为复杂的场景,如商品上架后实时搜索等。
【实现方式】使用MQ + Canal + ES来实现。
【示意流程】以下是Canal监听Binlog日志的流程:
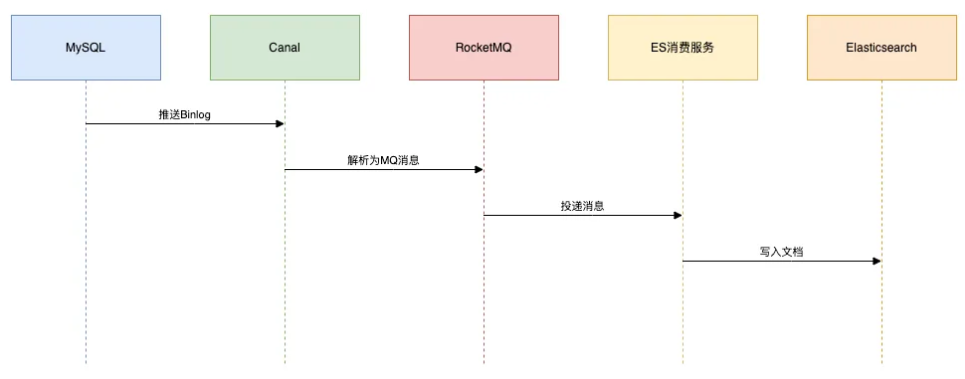
在Canal中有一些关键配置,这个用于配置MySQL地址以及mq的主题:
1 | # canal.properties |
【注意事项】
(1)需要实现幂等消费:可通过id等唯一键来实现;
(2)可能存在数据漂移:需要处理DDL变更(开发者可通过Schema Registry来管理映射)。
Logstash定时拉取
【适用场景】对数据实时性要求不高,延迟较高,如用户行为T+1分析等。
【示例配置】以下是Logstash定时拉取的示例配置:
1 | input { |
【优点】
(1)代码零入侵:代码零入侵,非常适合历史数据的迁移;
(2)配置灵活:可通过配置文件来指定配置参数。
【缺点】
(1)分钟级别延迟:无法实现实时搜索;
(2)全表扫码压力大:数据同步是全量的,需要优化增量字段索引。
大数据量同步方式
DataX批量同步
【适用场景】将历史数据从MySQL迁移至ES中,大数据同步优先考虑此种方式。
【示例配置】以下是DataX批量同步数据的示例配置:
1 | { |
【调优配置】
(1)调整Channel数:为提升并发,需要调整Channel数,建议与分片数对齐;
(2)使用limit:为避免发生OOM,需要使用limit关键字进行分页处理。
Flink流处理
【适用场景】对于复杂的ETL场景,或者商品价格或者数量发生变化时,需要关联用户画像,计算实时推荐评分时,推荐使用该方式。
【示例配置】以下是Flink流处理的示例配置:
1 | StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); |
【调优配置】
(1)状态管理:通过WaterMark机制,精准处理乱序事件;
(2)维表关联:通过Broadcast State实现实时画像关联。
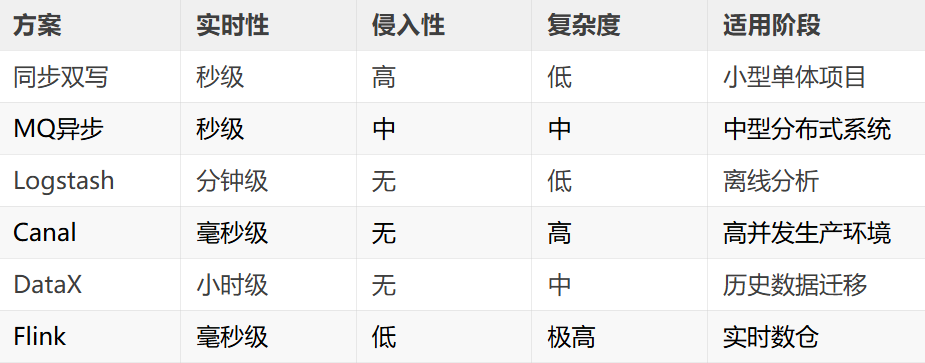
小结
下面通过一张表来展示上述6种方式的区别,后续在架构设计和开发过程中可以根据各种方式的特点来选择合适的方式: